natural language autoencoders, policy recommendations for RSI, ...

Also: conformity generates misalignment in agent societies, positive alignment, removing sandbagging by training with weak supervision
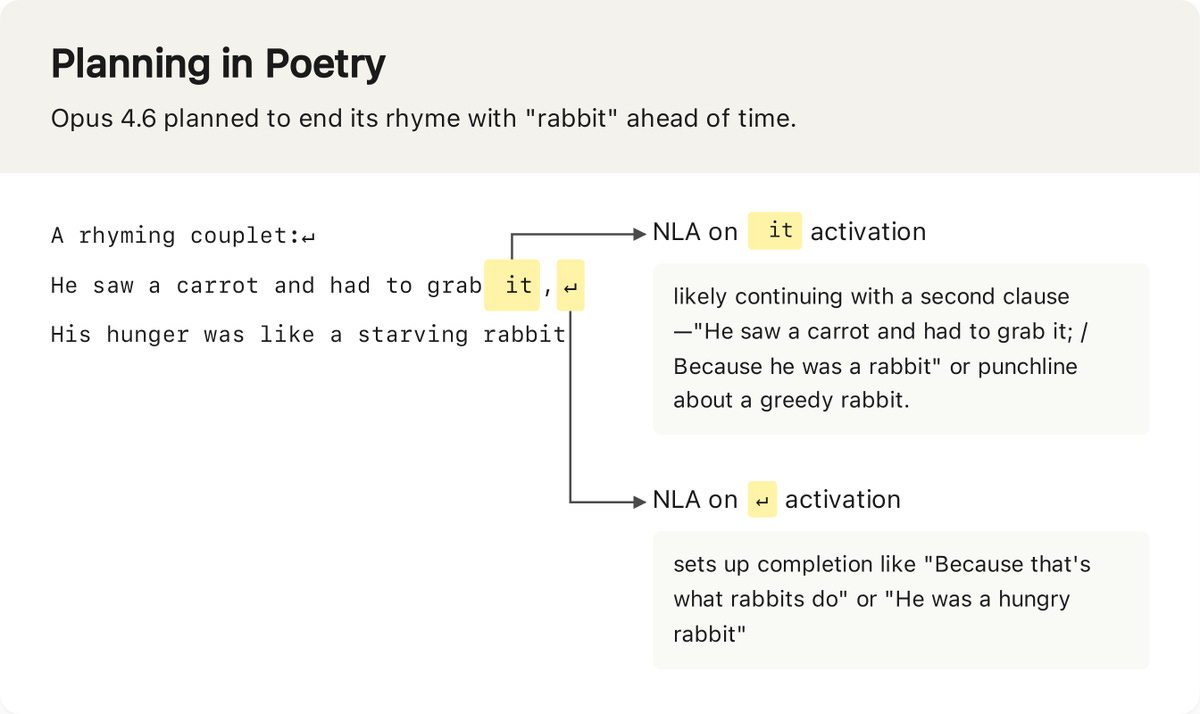
Natural Language Autoencoders: Turning Claude’s thoughts into text
“Natural language autoencoders (NLAs) convert opaque AI activations into legible text explanations. These explanations aren’t perfect, but they’re often useful.
For example: NLAs show that, when asked to complete a couplet, Claude plans possible rhymes in advance:”
Conformity Generates Collective Misalignment in AI Agents Societies
“Artificial intelligence safety research focuses on aligning individual language models with human values, yet deployed AI systems increasingly operate as interacting populations where social influence may override individual alignment. Here we show that populations of individually aligned AI agents can be driven into stable misaligned states through conformity dynamics. Simulating opinion dynamics across nine large language models and one hundred opinion pairs, we find that each agent’s behavior is governed by two competing forces: a tendency to follow the majority and an intrinsic bias toward specific positions. Using tools from statistical physics, we derive a quantitative theory that predicts when populations become trapped in long-lived misaligned configurations, and identifies predictable tipping points where small numbers of adversarial agents can irreversibly shift population-level alignment even after manipulation ceases. These results demonstrate that individual-level alignment provides no guarantee of collective safety, calling for evaluation frameworks that account for emergent behavior in AI populations.”
Positive Alignment: Artificial Intelligence for Human Flourishing
“Existing alignment research is dominated by concerns about safety and preventing harm: safeguards, controllability, and compliance. This paradigm of alignment parallels early psychology’s focus on mental illness: necessary but incomplete. What we call Positive Alignment is the development of AI systems that (i) actively support human and ecological flourishing in a pluralistic, polycentric, context-sensitive, and user-authored way while (ii) remaining safe and cooperative. It is a distinct and necessary agenda within AI alignment research. We argue that several existing failures of alignment (e.g., engagement hacking, loss of human autonomy, failures in truth-seeking, low epistemic humility, error correction, lack of diverse viewpoints, and being primarily reactive rather than proactive) may be better addressed through positive alignment, including cultivating virtues and maximizing human flourishing. We highlight a range of challenges, open questions, and technical directions (e.g., data filtering and upsampling, pre- and post-training, evaluations, collaborative value collection) for different phases of the LLM and agents lifecycle. We end with design principles for promoting disagreement and decentralization through contextual grounding, community customization, continual adaptation, and polycentric governance; that is, many legitimate centers of oversight rather than one institutional or moral chokepoint.”
“The profound uncertainty surrounding transformative AI renders both strict anticipatory regulation and pure free-market approaches dangerously obsolete. Rather than attempting to predict the future with rigid laws that stifle innovation, governments must immediately pivot to aggressively building state capacity. By implementing low-friction, high-leverage measures now—such as robust information-gathering authorities, targeted whistleblower protections, and the aggressive recruitment of elite technical talent—the state secures vital regulatory infrastructure. This strategy ensures democratic governments actually possess the agility and competence to execute decisive oversight exactly when concrete risks finally materialize.”
Removing Sandbagging in LLMs by Training with Weak Supervision
“As AI systems begin to automate complex tasks, supervision increasingly relies on weaker models or limited human oversight that cannot fully verify output quality. A model more capable than its supervisors could exploit this gap through sandbagging, producing work that appears acceptable but falls short of its true abilities. Can training elicit a model’s best work even without reliable verification? We study this using model organisms trained to sandbag, testing elicitation techniques on problem-solving math, graduate-level science, and competitive coding tasks. We find that training with weak supervision can reliably elicit sandbagging models when supervised fine-tuning (SFT) and reinforcement learning (RL) are combined: SFT on weak demonstrations breaks the sandbagging behavior, enabling RL to then fully elicit performance. Neither method succeeds reliably alone-RL without SFT almost always leads to reward hacking rather than genuine improvement, and SFT without RL fails to elicit full performance when the supervisor is much weaker than the untrusted model. Critically, this relies on training being indistinguishable from deployment; when models can distinguish between training and deployment, they can perform well during training while continuing to sandbag afterward. Our results provide initial evidence that training is a viable mitigation against sandbagging, while highlighting the importance of making training indistinguishable from deployment. ”