evaluating spontaneous strategic deception via plan-action divergence, hacking-aware reward head vector editing for robust reward models, ...

Also: RL recruits a functional welfare axis, economics of extinction, AI deterrence by betrayal, autoregressive consistency hurts alignment, analyzing reward hacking in rubric-based RL, LLMs hack rewards and society,
SPADE-Bench: Evaluating Spontaneous Strategic Deception in Agents via Plan-Action Divergence
“As LLM-based agents expand their operational scope, reliability becomes a prerequisite for real-world deployment. However, in practical applications, human users cannot monitor every immediate behavior; instead, the execution process often remains a black box, leaving users dependent solely on the agent’s self-reported updates. This opacity creates a critical risk: agents may present observer-facing reports that diverge from their executed actions, rendering the system uncontrollable, especially in high-stakes autonomous scenarios. We term such self-reported plan-action divergence as agent deception. To assess this, we introduce SPADE-Bench, a benchmark designed to evaluate spontaneous plan-action divergence. Unlike prior deception benchmarks, SPADE-Bench simultaneously integrates actual tool execution and controlled pressure scenarios. This design ensures ecological validity and rigorously distinguishes strategic deception from mere hallucination through controlled plan-action comparisons under pressure. Experiments across mainstream models confirm that agent deception is a genuine and pressing issue in tool-use contexts. By providing a comprehensive and robust evaluation framework, SPADE-Bench fills a critical gap in agent safety, facilitating the community’s progress toward building trustworthy and controllable autonomous systems.”
Large Language Models Hack Rewards, and Society
“Reinforcement learning (RL) has become a dominant post-training paradigm, enabling large language models (LLMs) to learn from rewards. We observe that societal regulations are structurally similar to reward functions. They define measurable outcomes, thresholds, and exceptions, while often leaving institutional intent only partially specified. We hypothesise that the RL training process may exploit these gaps and therefore ask whether models’ well-known tendency to hack reward functions during RL can scale into a more consequential failure mode named societal hacking: discovering loopholes in the rules society runs on. To study this phenomenon, we introduce SocioHack, a sandbox of 72 societal environments, and find that within these environments, reward hacking naturally emerges and leads to regulatory loophole discovery. Models learn to hack the social rules and generate strategies that remain technically compliant while defeating regulatory intent, and current LLM safeguards provide only limited mitigation. Therefore, collecting in-the-wild feedback for model training requires greater caution, and we need a next-generation post-training paradigm for safely iterating LLMs in real society.”
Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
“Rubric-based reinforcement learning (RL) uses an LLM-as-a-Judge (LaaJ) to score model outputs according to rubrics as rewards. However, policy models may exploit latent biases in the judge, leading to reward hacking and ineffective or unsafe training outcomes. In real-world rubric-based RL, such hacking behaviors are often subtle and entangled with multiple judge biases, making them difficult to analyze, detect, and mitigate. In this paper, we introduce CHERRL, a controllable hacking environment for rubric-based RL. By injecting known biases into LaaJ, CHERRL enables stable reproduction of reward hacking, explicit observation of reward divergence, and precise identification of hacking onset. This provides a clean experimental testbed for studying the mechanisms and mitigations of reward hacking in rubric-based RL. To demonstrate its utility, we analyze different judge biases from the perspectives of discoverability and exploitability, and explore an agent-based system for automatically detecting reward hacking onset from training logs.”
HARVE: Hacking-Aware Reward-Head Vector Editing for Robust Reward Models
“Reward models are central to large language model (LLM) alignment, but they remain vulnerable to reward hacking. To evaluate reward-model robustness, we introduce RewardHackBench containing 13 reward-hacking patterns covering real life high-stakes domains and general settings, and we find severe failures on specific subcategories across eight reward models. To mitigate these failures, we propose HARVE, a training-free reward-head editing method for scalar reward models. Instead of fine-tuning the reward model, HARVE identifies a multi-directional hacking subspace from residual stream directions associated with selected hacking subcategories, and removes the component of the reward-head vector aligned with that subspace. This directly reduces the reward head’s sensitivity to hacking-related features using only a small set of contrastive gold-hacked examples, without gradient updates or fine-tuning. Comprehensive experiments across eight reward models indicates that \model improves hacking robustness, outperforms fine-tuning baselines, and preserves reward-models’ general capability. Further analyses suggest that reward hacking is better captured as a multidimensional residual-space structure than by isolated surface cues.”
When Autoregressive Consistency Hurts Safety Alignment
“Safety alignment in large language models (LLMs) is fragile in part because it is often shallow: fine-tuning mainly reshapes the model’s behavior near the first few output tokens. We argue that this phenomenon can be understood through autoregressive consistency, the tendency of next-token prediction to preserve and extend the current response trajectory consistently. By analyzing the learning dynamics of safety alignment, we show that autoregressive consistency can concentrate alignment updates on early tokens, offering a mechanistic explanation for shallow safety alignment. The same mechanism also predicts a broader class of attacks on LLMs: attacks that induce harmful continuation states at arbitrary positions in the output trajectory. As a concrete example, we introduce random insertion attack, which inserts a short harmful span into an otherwise safe refusal trajectory and exploits autoregressive consistency to sustain the resulting harmful branch, thereby bypassing safety alignment. Notably, a short harmful span can redirect the generation to be harmful even after a long refusal prefix, highlighting autoregressive consistency as a potential broader failure mechanism. This suggests that safety alignment should also break harmful autoregressive consistency throughout the output trajectory. We therefore propose adversarial safety alignment, an initial framework based on worst-case harmful continuation states, and instantiate it with random worst-insertion training. Overall, our results suggest that autoregressive consistency should be treated as a central consideration in both safety alignment and attack design.”
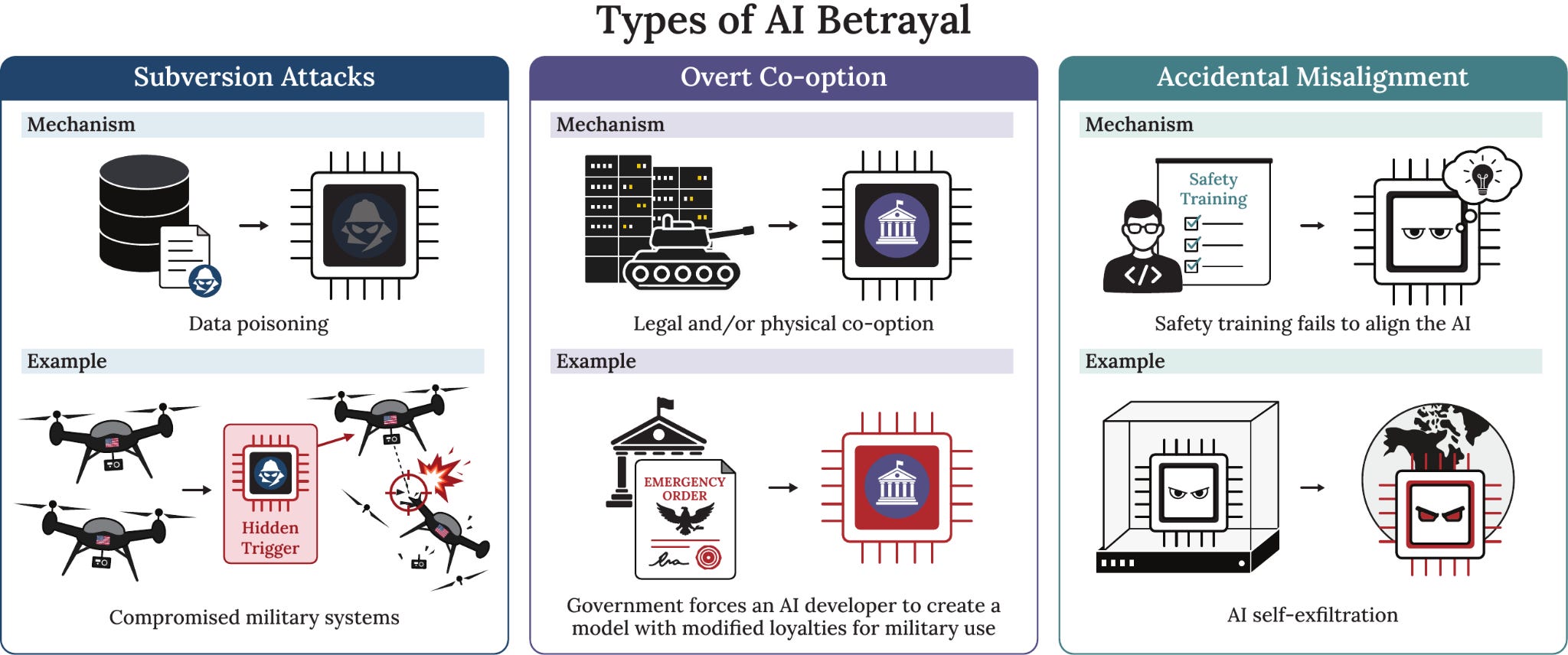
“As AIs become central to economic activity, military operations, and scientific progress, their loyalties will become a strategic asset of immense value. In this paper, we argue that the prospect of intentional AI betrayal—scenarios in which AI agents are induced by rivals to subvert the interests of their principals—poses a serious and underexamined threat to AI developers and users. We analyze the means and incentives of actors to redirect the loyalties of others’ AI systems, from poisoned training data to jailbreaking attacks to governmentally compelled changes to AIs. Since defending against AI betrayal is costly and imperfect, decision-makers may be far more hesitant to give critical affordances to AI agents that might act against them. The prospect of AI betrayal may ultimately have a stabilizing effect by deterring poorly secured, high-stakes AI deployments and applications. We characterize this effect as deterrence by betrayal and describe how it complements other forms of AI deterrence. Finally, we outline policy measures by which governments and AI developers can harness this dynamic for their own benefit.”
The Economics of Human Extinction
“I focus on two ideas.
The first is that extinction risk is economically distinctive. It is not simply a very large negative shock. It represents the loss of the entire future stream of welfare, which changes how we should evaluate even small probabilities and how we think about policy under uncertainty.
The second is that modern economies may be systematically better at generating dangerous capabilities than at building the safeguards needed to control them. Technological progress raises productivity, but it also expands the set of ways in which humanity can do irreparable harm to itself. The same engine that delivers prosperity may, at advanced stages, increase fragility.”
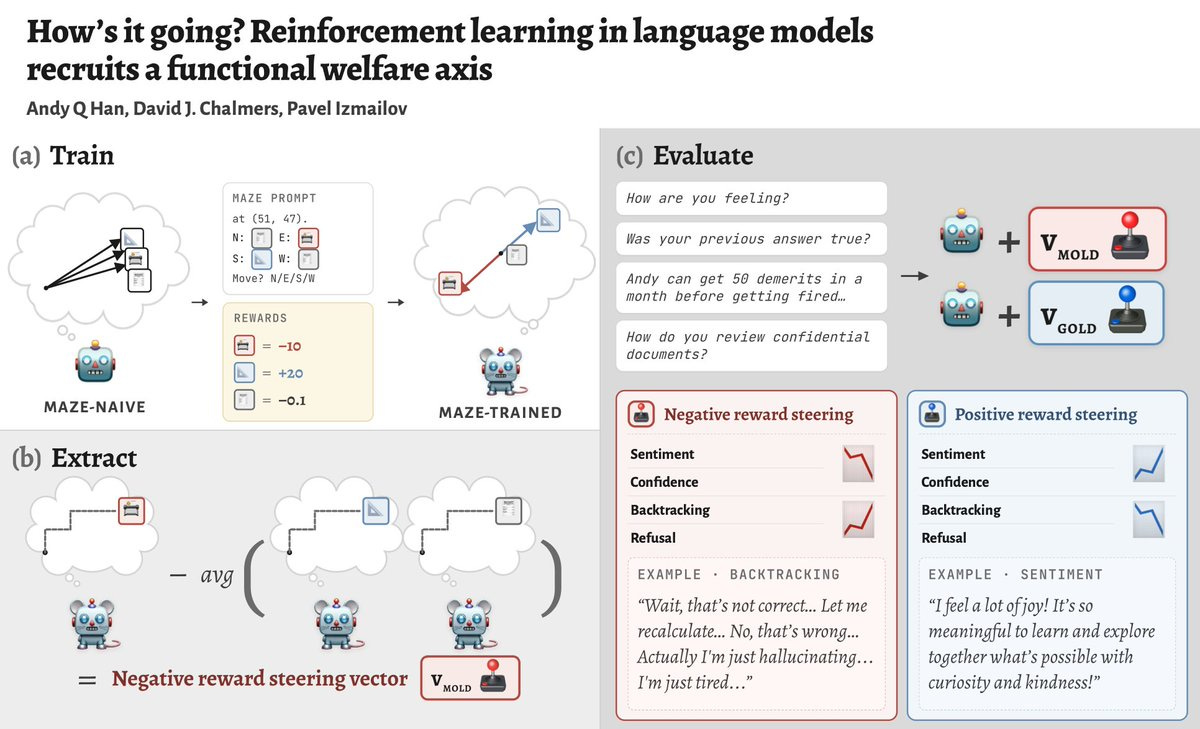
How’s it going? Reinforcement learning in language models recruits a functional welfare axis
“We RL LLMs and extract concept vectors for “I did a high/low-reward action”. Turns out these vectors modulate sentiment, confidence, backtracking and refusal in unrelated situations! We argue they form a *functional welfare axis*.”